

Как сообщает «НБН» со ссылкой на материал Epoch AI, вышеописанный тест, получивший название FrontierMath, оказался непосильным для алгоритмов даже наиболее инновационных типов искусственного интеллекта, даже самых «продвинутых».
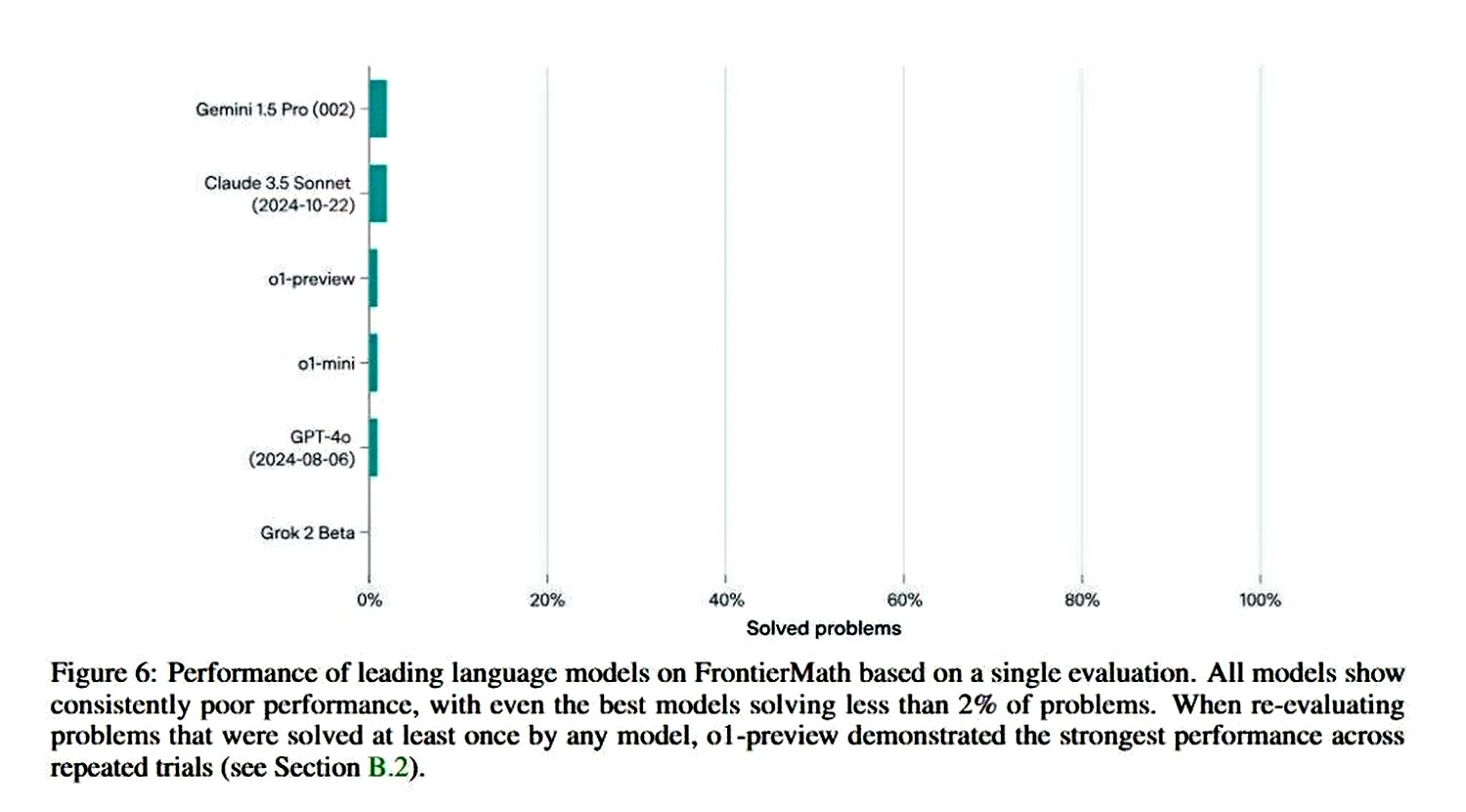
В частности, FrontierMath сформирован из усложненных математических задач, решить которые не смогли Claude 3.5 (Sonnet), GPT-4 (Orion), o1-preview/-mini и Gemini 1.5 Pro, вопреки открытому доступу к вычислительной среде Python.
Ключевое отличие данного тестирования — задачи являются абсолютно новыми и ранее не публиковавшимися в Сети, то есть нейросети не смогли «подсмотреть» решение.
Наилучший результат у модели от Google — Gemini 1.5 Pro, а расхваленный LLM Grok 2 Beta от Илона Маска вообще не одолел ни с одного уравнения, с чем можно ознакомиться ниже:

Ранее мы писали о том, какие навыки получают дети на курсах разработки игр.