


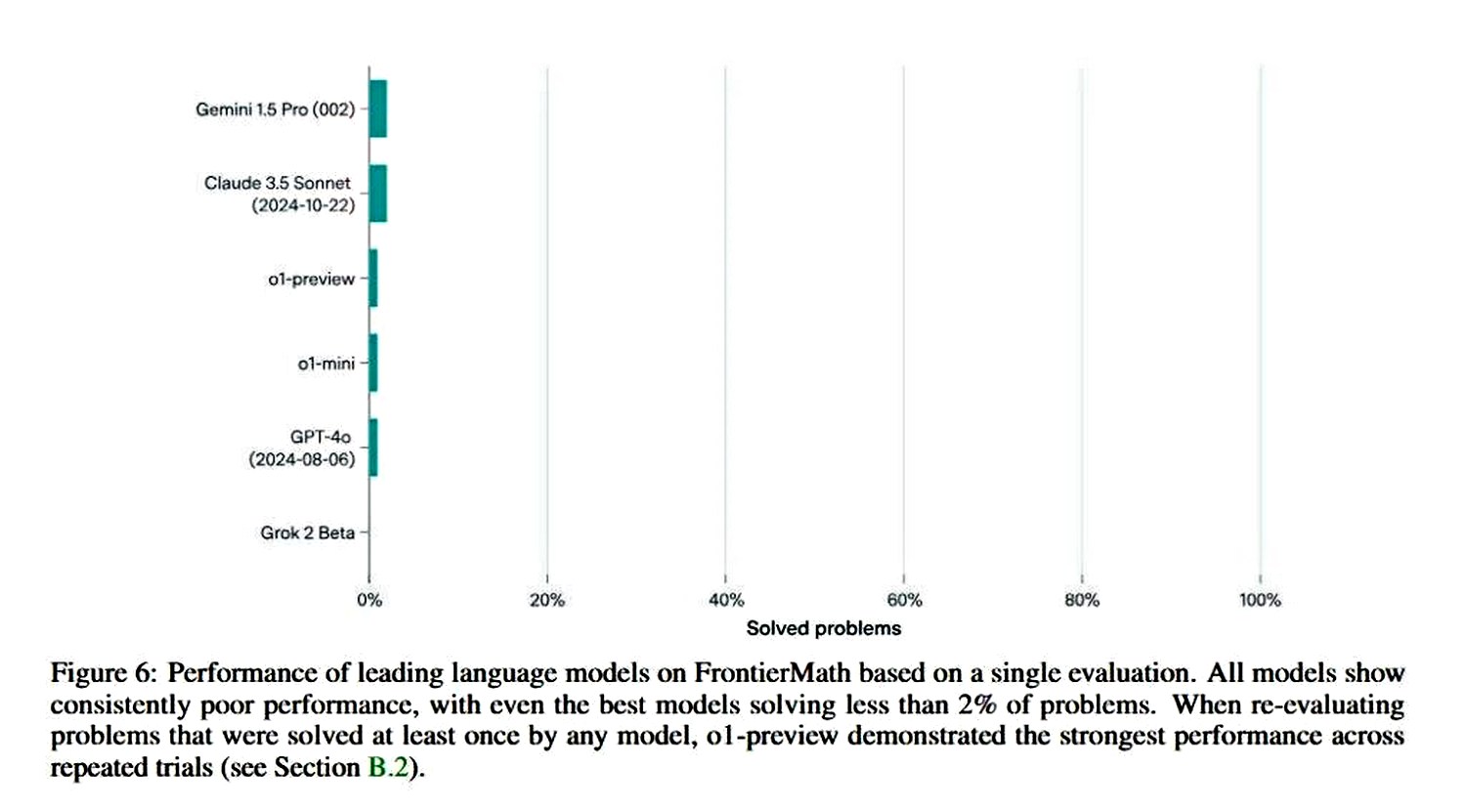
Як повідомляє «НБН» із посиланням на матеріал Epoch AI, вищеописаний тест, що отримав назву FrontierMath, виявився непосильним для алгоритмів навіть найбільш інноваційних типів штучного інтелекту, навіть найбільш «просунутих».
Зокрема, FrontierMath сформовано з ускладнених математичних завдань, розв’язати які не змогли Claude 3.5 (Sonnet), GPT-4 (Orion), o1-preview/-mini та Gemini 1.5 Pro, всупереч відкритому доступу до обчислювального середовища Python.
Ключова відмінність цього тестування — завдання є абсолютно новими й раніше не публікувалися в Мережі, тобто нейромережі не змогли «підглянути» рішення.
Найкращий результат у моделі від Google — Gemini 1.5 Pro, а розхвалений LLM Grok 2 Beta від Ілона Маска взагалі не здолав жодного рівняння, з чим можна ознайомитися нижче:

Раніше ми писали про те, які навички отримують діти на курсах розробки ігор.